The Virtual Research Assistant#
Data Journey: From Telescope to Transient Name Server#
See also
Survey Design: Tonry et al. 2018 | Transient Server Smith et al. 2020
The ATLAS data are first reduced (debiased and flat fielded) on site before being sent to Hawaii for difference imaging. Alerts are produced if a detection above 5 sigma is recorded, and these form the data stream that is handled by the servers at Queen’s University Belfast.
The alert stream size is of order 10s millions per night. Most of these are artefacts from the difference imaging process, or known variable stars. The stream processing steps are:
Alerts to Sources: We aggregate individual alerts into sources (one source will likely have mutiple alerts). If the source is new, its unique 19 digit ATLAS ID is created.
Basic Cuts: Some simple quality cuts can help reduce the volume of the data stream. The main requirement is that at least 3 detections per source (per night) are required to move onto the next stage.
Sherlock catalogue cross matching and remove variable stars.
Real/Bogus Score: We use a Convolutional Neural Network to classify the alerts as real or bogus (see Weston et al. 2024 ). If the RB score >0.2 they are passed on to eyeball list
Eyeball list: The alerts are eyeballed and classified as
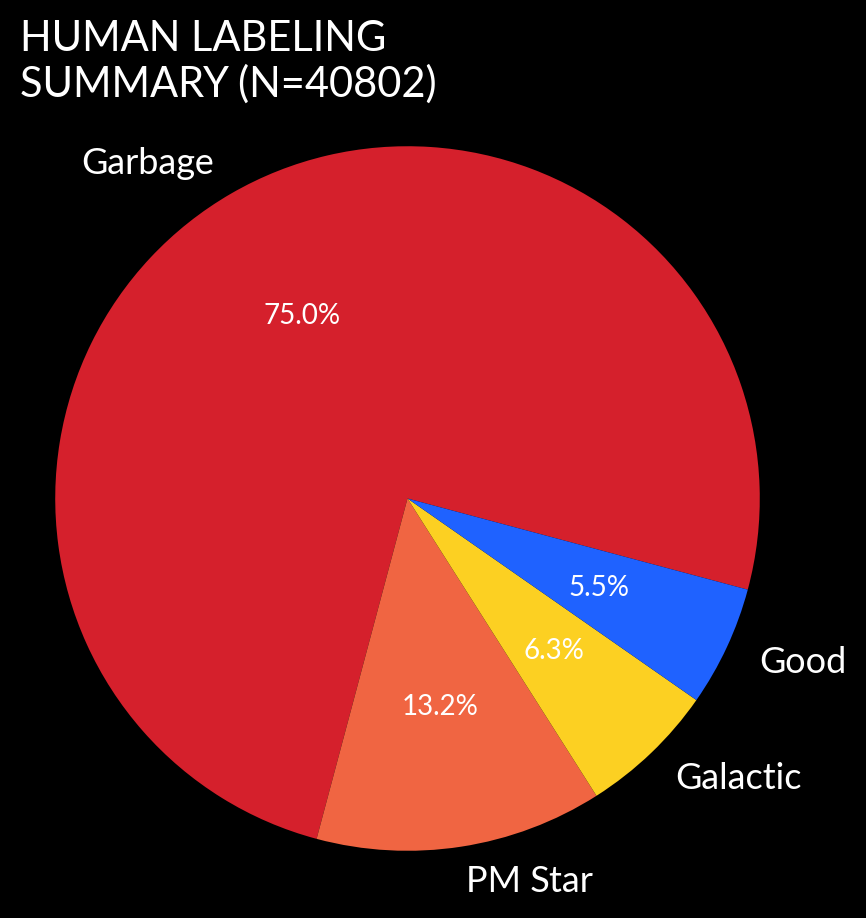
garbage,pm(proper motion star),goodorattic(for real alerts from transients within the galaxy). Good alerts are automatically pushed to TNS.
The eyeball list in ATLAS still receives between 1000 and 3000 alerts every week depending on weather and phase of the moon. Despite the fact that the CNN removes 98.5% of alerts, most of the eyeball list is still garbage.
The Challenge of Automation#
The difficulty in automating the eyeballing process further is two fold:
We need very high completeness (we don’t want to miss cool transients)
Humans are FAST at the eyeballing task. Meaning they need little data
Important
Given the cadence of ATLAS, people making over 90% of decisions within 24/48 hours means they most often only have one to two lightcurve points to look at.
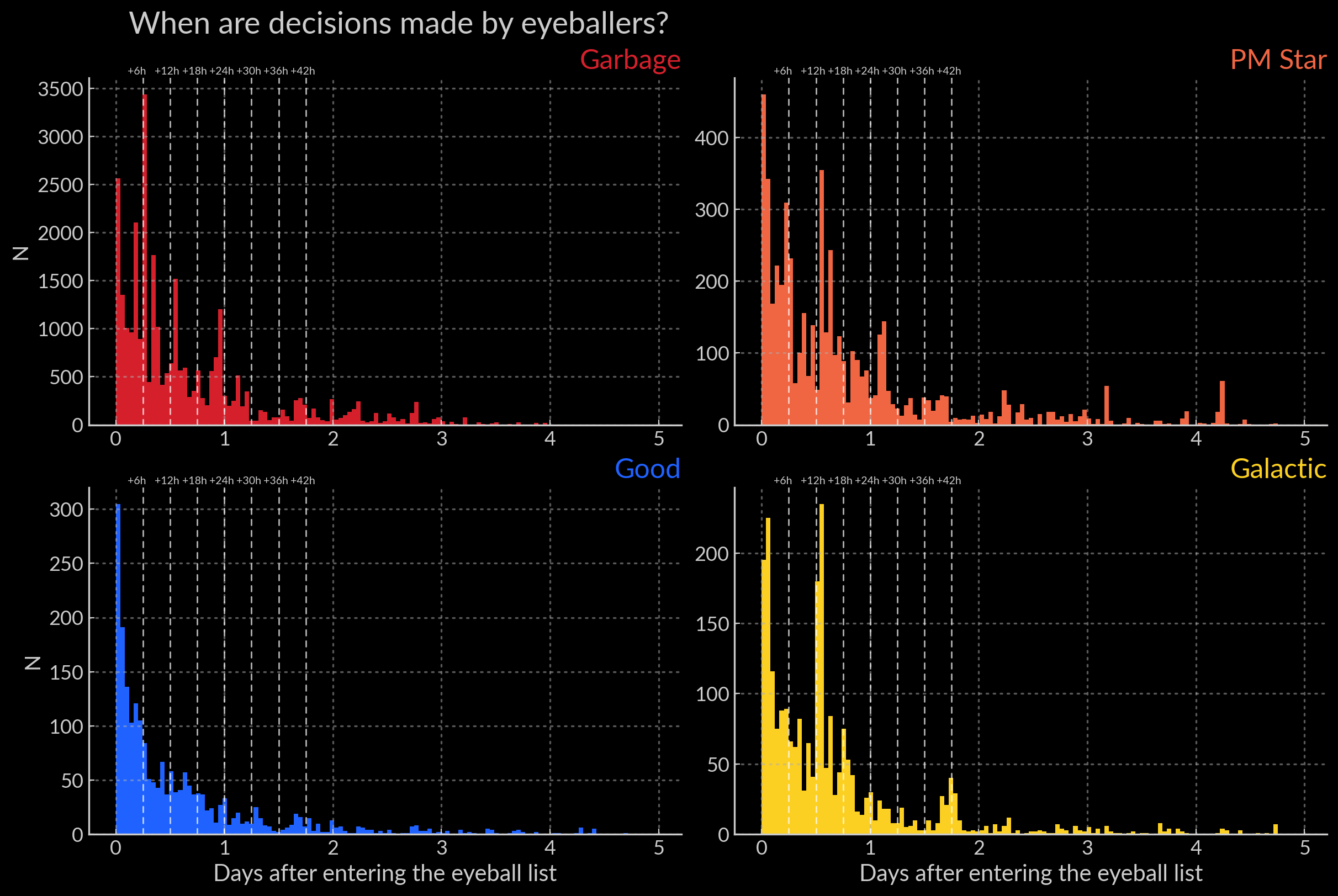
Histograms split by types showing the delay in human decisions#
Because lightcurve information is spares, classic transient classifiers made to reproduce spectroscopic classifications using only the lightcurve information are never going to have sufficient information to be useful in this regime. We therefore need to bridge the gap between the Real/Bogus classifiers (day 1 regime) and the Transient classifiers (day 7+ regime).
The VRA is designed to emulate the decision making of the eyeballers,
and to leverage as much of the data available on the web server as possible.
In addition to using the RB score, the virtual eyeballer st3ph3n also uses
context and lightcurve features and it follows a similar strategy
to the human team by asking two questions:
Does this alert look REAL?
Does this alert look GALACTIC ?
Real and Galactic Scores#
To calculate the Real and Galactic scores, we train models called Histogram base Gradient Boosted Decision Trees (see scikit-learn docs ). Both models use the same features but they calculate scores independently, and they are trained separately.
They each score the alerts from 0 to 1, such that we can place our alerts in a plot we call the score space:
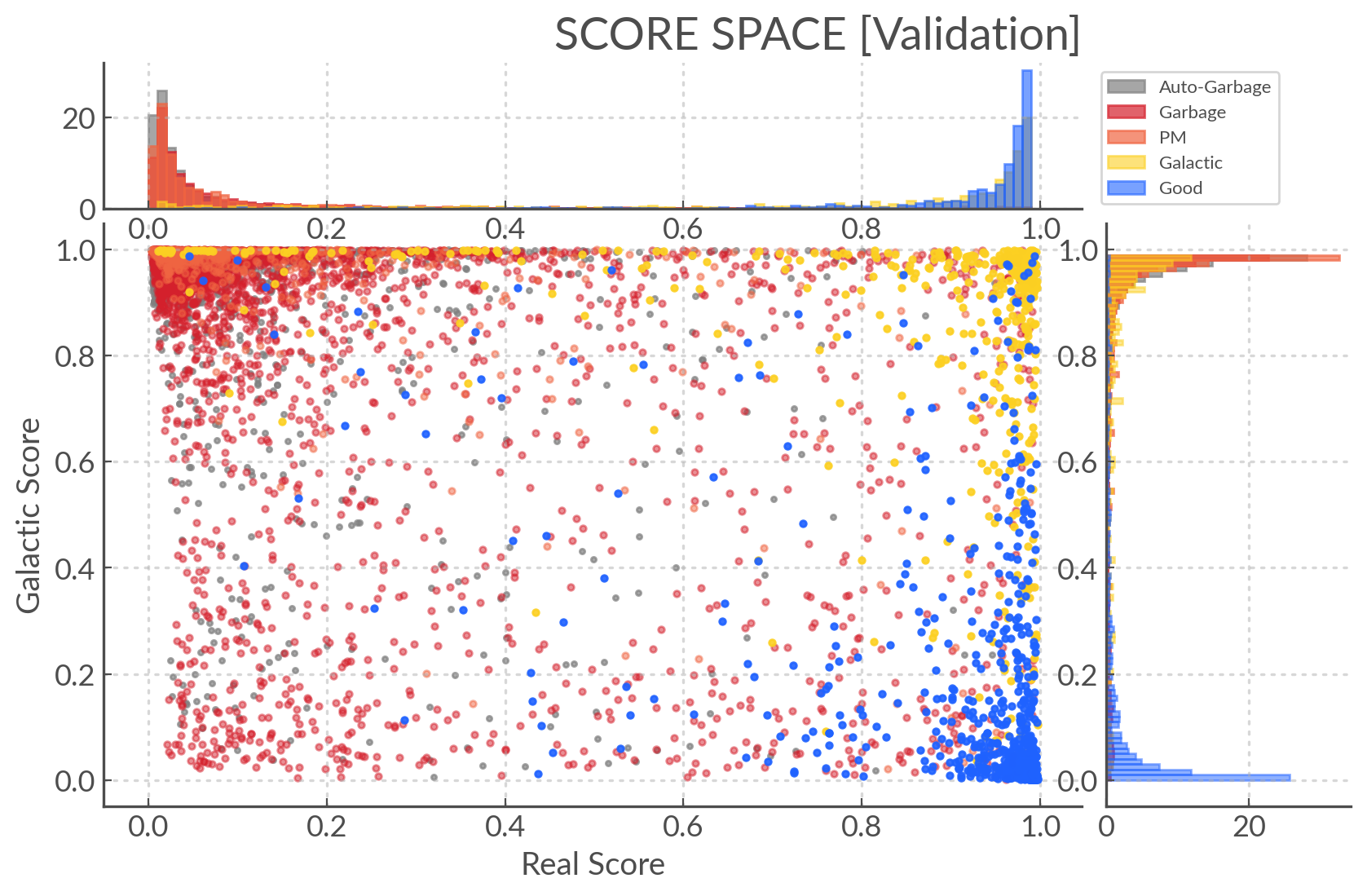
Score space showing the balanced training data for the Crabby models#
Because we care about extragalactic transients we are interested in alerts nearest the bottom right (real=1, galactic=0). We’re going to use this to calculate the ranks.
Finally, the alerts are scored again every time new data is available.
There is a distinction between the models that score when first entering the eyeball list (day1 models)
and those updating the ranks on future visits (dayN models), in that the latter
use additional features (see the Data section). But the ranking logic remains the same.
Ranking#
To rank our alerts we now use a geometric distance (with a few extra shenanigans). The bottom right hand corner of the plot is the “most” Real and Extra-galactic. Hypothetically that is the alert we care about the most. To calculate the ranks we therefore calculate the distance to that (1,0) point. Then:
- I scale the galactic axis by 0.5 to separate the garbage from the real alerts more effectively.
It also ensures our eyeballing policy (see below) encompasses the real=1, galactic=1 corner.
- To get a score between 0 and 10 you also have to invert the distance (the smaller the distance the higher the score),
normalise by the diagonal of the plot and multiply by 10.
Important
TL;DR: The closer to the Real-ExtraGalactic corner (1,0) - the higher the rank. A rank = 10 is a special case were a TNS crossmatch has been found.
Policies#
The goal of the VRA is to reduce human workload so now that we have the ranks we need to decide
Which alerts are worth asking the humans to eyeball
Which ones we can ditch automatically
Note
Nothing is deleted from the server when an alert is garbaged. It’s just tagged as garbage.
Eyeballing#
The current eyeballing policy is to ask human experts to check everything
with a rank >7 (as an extra-galactic transient candidate) and everything that
falls within a distance of 0.40 (galactic axis scaled by 0.9) of the coordinate (1,1) as a galactic candidate.
You can see below where these strategies fall in score space with respect the
the distribution of our alerts in our training and validation set.
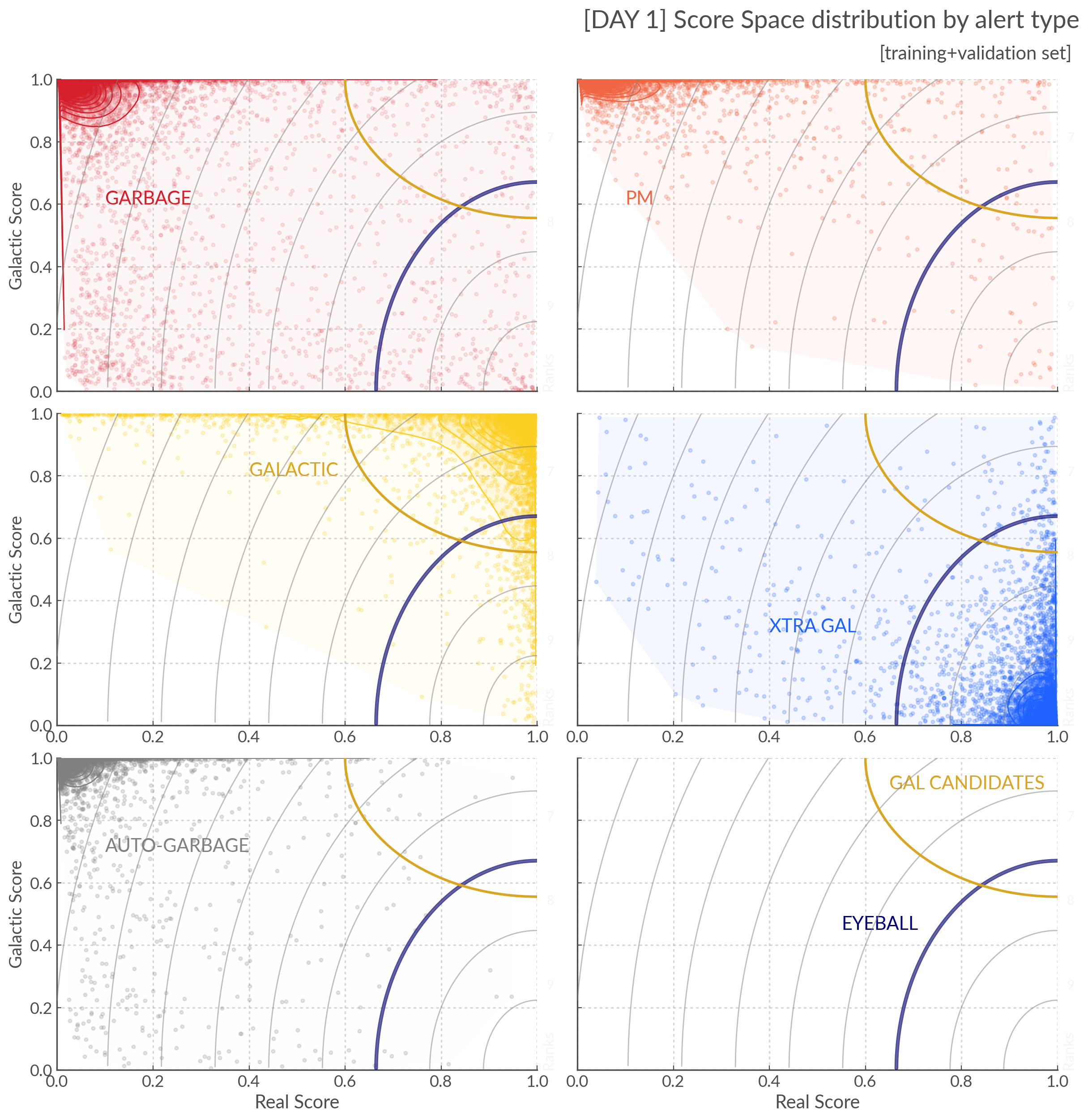
Here we show the score space distributions for each alert type. We also plot the VRA rank contours.#
Warning
Due the the distribution of the galactic alerts extending quite far down the Real axis, this policy means that a non negligible fraction of galactic transients will be missed. See the discussion at the bottom of this page for more info.
Garbaging#
There are currently three “garbage collection” policies in place:
On entering the eyeball list with
rank<1.5On a second visit,
max(rank)<2.0.On the third and subsequent visits,
mean(rank)<3.
Because the cadence is often 2 to 3 days, after the 3rd or 4th visit we will
get close to +15 days after initial alert, which falls out of the training window.
Because we eyeball everything with rank >7.5 these garbaging policies will leave some alerts in
what is called the “purgatory”.
These are now being handled by el01z (see the Monitoring section) which has a sentinel looking out for
alerts that are left in purgatory after they have fallen out of st3ph3n ‘s training window.
There are few of those and they are sent to the slack for eyeballing.
Resources#
Data Release [Upcoming]
Paper [Upcoming]