The Data#
The current family of models is called Duck and encompasses
data gathered between 2024-03-27 and 2024-01-22.
It is a super-set of the Crabby data gathered between 2024-03-27 and 2024-08-13,
with an additional few months of data gathered between 2024-08-18 and 2025-01-22.
Note
The naming convention is as follows: new names are chosen for new data sets(not new features), with their names starting with incremented letters of the alphabet. The Duck data-set is the fourth iteration of the VRA training set.
The start date corresponds to our implementation of the systems that record human decisions as they are being made. We chose to only train on alerts whose data could be recorded as the human decisions were being made so that we have a truthful record of what they looked like at the time.
Because of updates in e.g. the Sherlock cross-matching in some
older data in the database, recreating the conditions under which each alert
was eyeballed is non trivial and since we get a constant influx of new data,
we opted for the thrifty option of using data we could control fully.
The August cut off is chosen such that these data are not affected
by any human-machine interaction considerations.
The data downloaded is what is returned by the ATLAS API, for the schema you can check the json schema. It is cleaned up into a few csv files:
contextual_info_data_set.csvdetections_data_set.csvnon_detections_100days.csvvra_last_entry_withmjd.csv
See also
You can get the data and the codes used to clean it up [HERE ADD ZENODO]
Some Caveats#
Most human-labelled alerts were handled by only one eyeballer (apart from a few exceptions posted on slack and the 2000 or so I re-eyeballed). Ideally for a well curated data set we would want two to three opinions especially for borderline cases. Here are a few ways this will affect the current data:
Not all eyeballers use the Proper Motion star list. They will just put proper motion alerts in the garbage. This will lead to some confusion between the
garbageandpmalerts. This is not a big deal sincegarbageis not longer used as a “NOT GALACTIC” label and is ommited from the galactic classifier training set.Most eyeballers will put galactic events in the
goodlist if another team has mistakenly added those to the TNS. This will lead to some confusion between thegalacticandgoodalerts.
The
galactictag is actually anatticlist tag. But the attic list also used to contains the following which will lead to further confusion between thegalacticandgoodalerts:Duplicate supernovae (As of 2025-01-30 we have a duplicate list so they will no longer be in the attic; this will not affect future datasets bu it affects all of Duck)
Suspected AGN activity
Training and Validation sets#
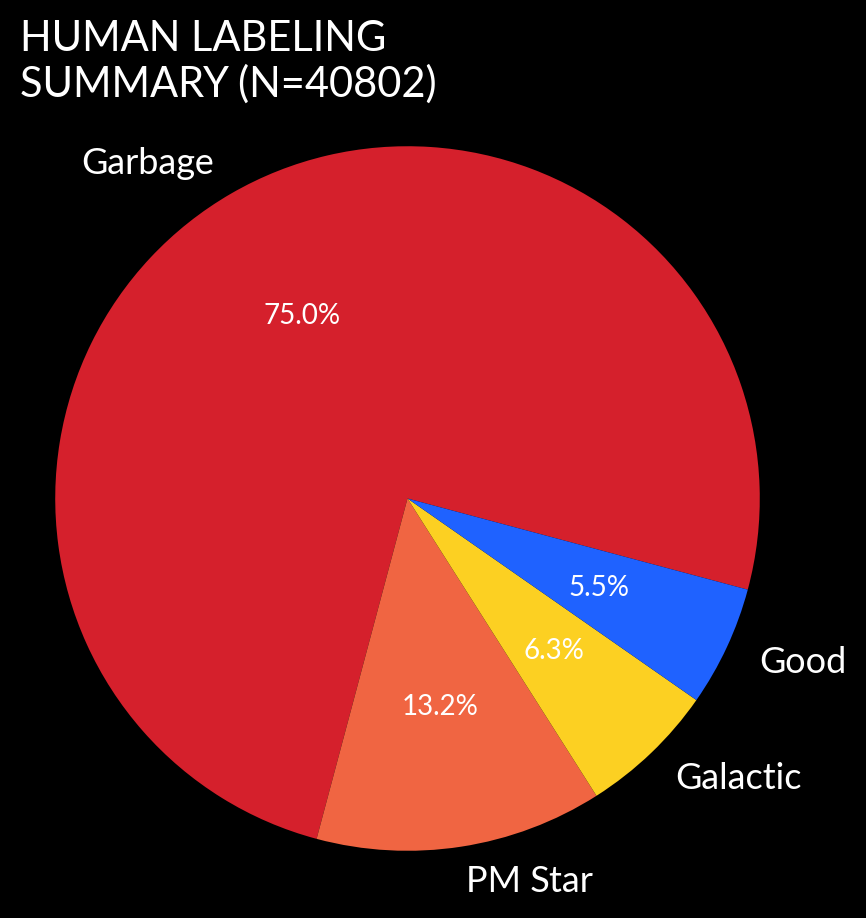
The data eyeballed over the period covered by crabby includes over
40,000 alerts, 88% of which were either Garbage or Proper Motion stars.
Roughly 5.5% were classified as good and 6.5% as galactic (i.e. put
in the attic).
In the additional data set included in Duck we have over 34k new alerts
but a significant fraction that were auto-garbaged - handled automatically by the VRA.
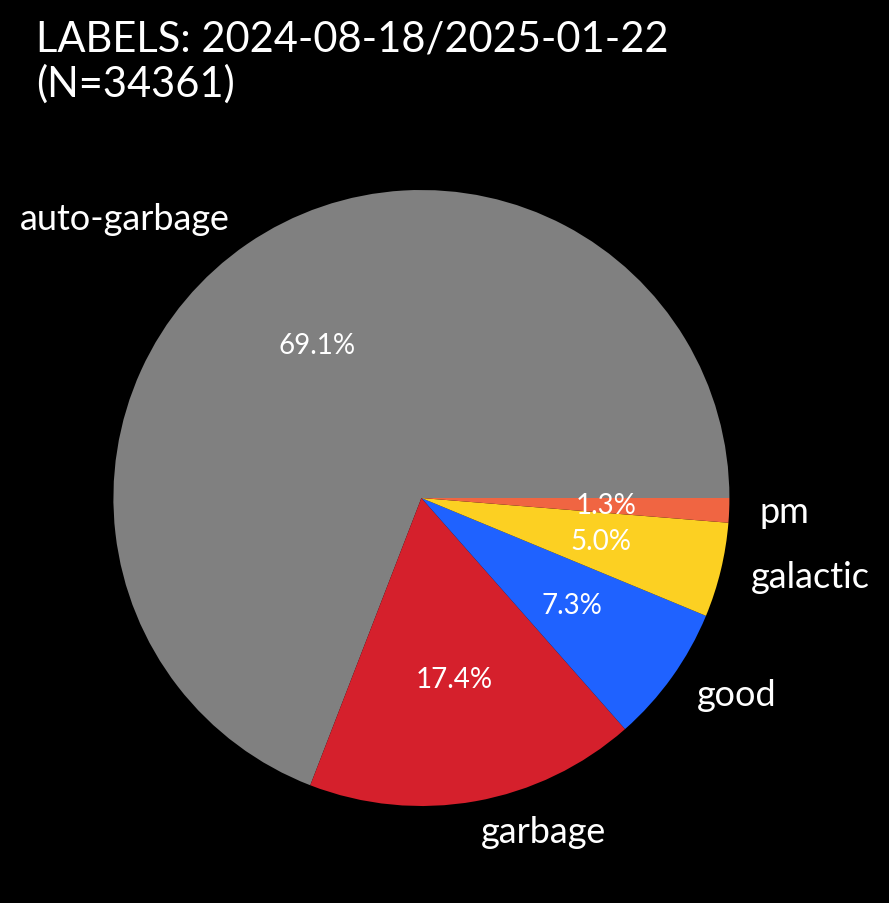
With these data we create a (somewhat) balanced training set and an unbalanced validation set that we will use to check that our models generalise decently and to tune some hyperparameters. We do this by randomly sampling 15% of our alerts before balancing to be our validation set.
We then balance what’s left to make our training set.
We use undersampling of the larger categories (pm and garbage)
rather than oversampling of the smaller categories.
I started with that because I didn’t want to duplicate data and the models
were working decently with just a few thousand samples, but oversampling
has not actually been tested and compared.
When making the Duck validation set I do not re-sample the whole dataset from
March 2024. Instead I take the same validation set as in Crabby and sample
from 15% of the extra data from August 2025 onwards.
Note
We do not call it a test set because it isn’t : we use it to check our models hyperparameters and decided if we want to keep or add features. A real test set is an unseen data set we only use to calculate performance metrics. Realistically, we test in prod.
We keep the validation set unbalanced so that it is representative of what the model will see in production so that the metrics we calculate to check performance and generalisation are representative of what we might see in real life.
The number of alerts in our training and validation sets are shown in the
table below. As you can see the training set is slightly unbalanced
with 300 more garbage, pm and galactic alerts than good alerts.
That’s because I wanted to keep as large a training set as possible
so I balanced based on the number of galactic alerts. The slight imbalance
did not affect the model’s performance in early tests (but we did
try training on the unbalanced training set and it was a disaster).
The training set is not fully balanced because I didn’t want to downsample Good objects
in the additional data available in Duck.
The Features#
Day 1 models#
The day1 models are those that calculate the initial real and galactic
scores when an alert first enters the eyeball list.
They currently use the following features:
Category |
Feature |
Description |
|---|---|---|
Light curve long term history (last 100 days) |
|
Standard deviation of the number of non detections between each detection |
|
Mean of the number of non detections between each detection |
|
|
Standard deviation of the magnitude of each historical detection |
|
Light curve recent history (last 5 days) |
|
Number of detections |
|
Number of non detections |
|
|
Median magnitude of the detections between phase -5 d and day 1 |
|
Positional scatter recent history (last 5 days) |
|
Log10 of the standard deviation of the RA |
|
Log10 of the standard deviation of the Dec |
|
Contextual Information |
|
Right Ascension |
|
Declination |
|
|
Real/bogus score from the CNN |
|
|
Spectroscopic redshift |
|
|
Photometric redshift |
|
|
E(B-V) (extinction in magnitudes) |
|
|
Log10 of the separation in arcsec from a nearby source |
|
Boolean flags for the following sherlock feature: |
|
Known Cataclysmic Variable |
The Sherlock features SN, ORPHAN, NT, UNCLEAR, as they are not found to
be informative. It’s unsurprising as we are providing information used by sherlock to create those tags
(such as the separation from the nearby source or the redshift) so it uses those and not the boolean flags.
CV is useful to an extent because it’s a direct classification (but often the VRA can guess it’s galactic).
Day N features#
The dayN models update the real and galactic scores when new
information becomes available, that is, when ATLAS has visited that part of the
sky again and has either seen something or seen nothing (Either way
it might tell us something about the event).
The dayN models use all the features of the day1 models plus
an additional set of lightcurve features to try to capture the evolution
of the lightcurve.
Note
The dayN features are calculated from -5 days to +15 days w.r.t
the alert date.
Feature |
Description |
|---|---|
|
Number of detections since phase -5 d |
|
Median magnitude of the detections since phase -5 d |
|
Median magnitude of the non detections since phase -5 d |
|
Number of non detections since phase -5 d |
|
Maximum (median) magnitude seen since phase -5 d |
|
Day of the maximum magnitude |
The features DET_N_today, NON_N_today.
were pruned as they were found to be useless (even in the previous iteration of the model).
It makes sense that these features are not useful: The number of detections or non detections today
is just a subset of the total number of detections or non detections.
Note
Technically taking the median of a magnitude is not the proper way to bin a magnitude. But it’s quick and good enough and we have to do these operation over and over. There is nothing to gain from going into flux space and binning in there.
Forced Vs Unforced Photometry#
The light curve features are calculated on the unforced photometry. This is quite limiting and in future iterations we will need to include forced photometry to get more useful features. The relation between detections and non detections changes with weather and the phase of the moon. I tried to capture that by having features that count both and measure both. But this is a loosing battle.
We need forced photometry to do a decent job of the lightcurve features. The challenge is that forced photometry is expensive to calculate so we don’t want to do that on everything in the stream.
Feature Importance#
The features described above were chosen based on my conversations with the eyeballers and my own eyeballing experience, but whether and how much they contribute to the model is only something we can assess once we have trained them.
To explore that we can look at the permutation importance of our features. The basic concept is simple: you take a feature column and shuffle it. Then you retrain the model and see how much worse the predictions are. The worse you do when you scramble a feature, the more important that feature is.
Real ScoreModel - day1 Features#
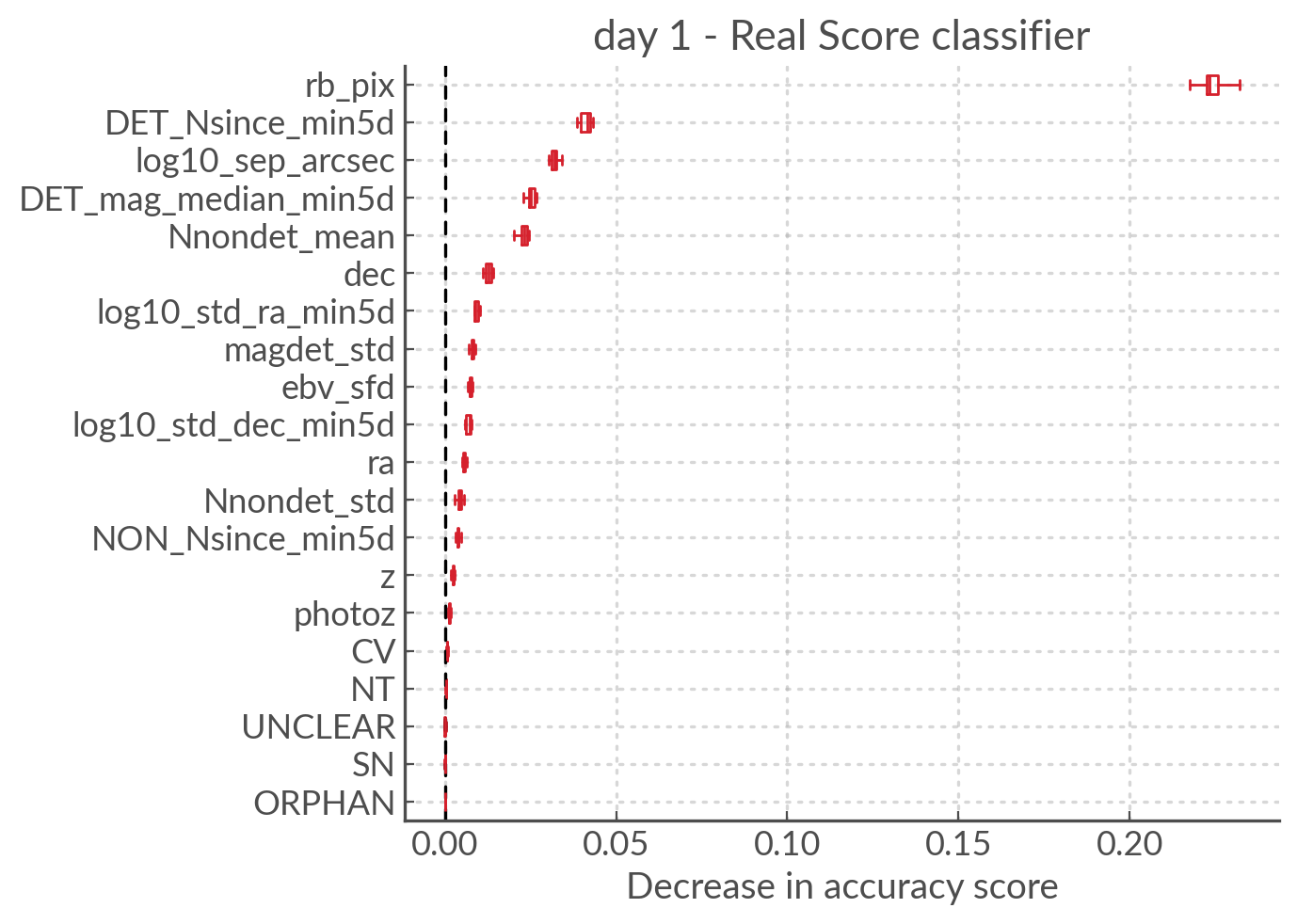
Permutation importance of the day 1 features for the real scoring model#
rb_pix being the most important feature is not surprising.
But some of the other important features may seem a bit odd. Why would the
log10_sep_arcsec be so high on the list? Likely because
bad subtractions and artefacts from proper motion stars happen in
the vicinity of the cross matches.
RA and dec are also very important because bogus alerts are often
found in the galactic plane (note in BMO, a previous version, we did try
to use the galactic coordinates to do the training but it gave worse results!).
ebv_sfd is also somewhat significant, likely because it’s a proxy for the
galactic plane and crowded fields that yield more artefacts
rather than extinction directly causing bogus alerts.
Some features like z and photoz are not important here (as expected),
but they will be for the galactic model which is why they’re included.
Galactic Score Model - day1 Features#
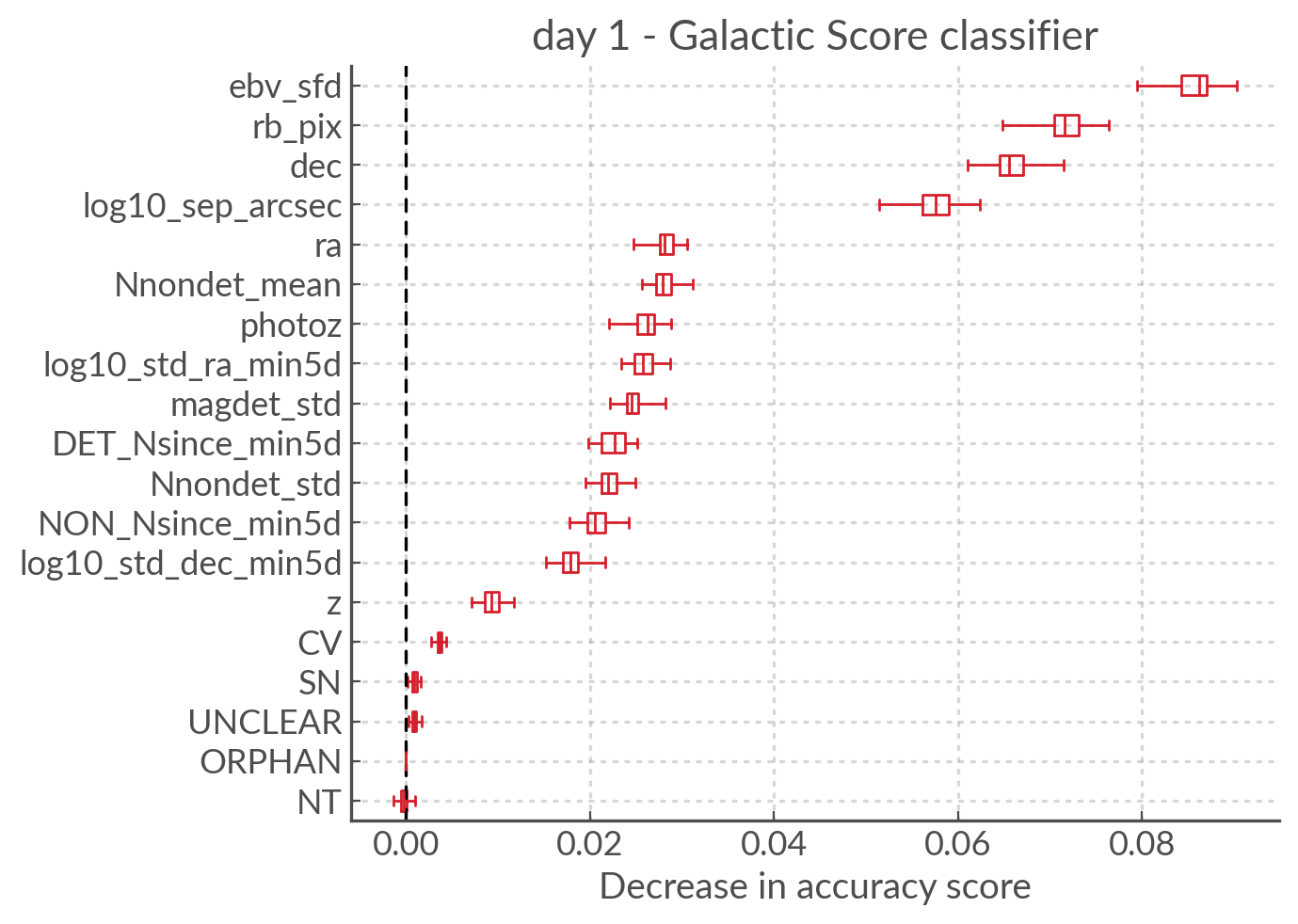
Permutation importance of the day 1 features for the gal scoring model#
For the galactic scores, the most important feature is ebv_sfd, as
one might expect (since anything with too high an extinction will automatically
and safely get a galactic tag).
rb_pix is also important, which is somewhat surprising but likely a result
of how RB score is affected by bad subtractions in the galactic plane or by
proper motion star.
Again log10_sep_arcsec is important, and I suspect it is a proxy for
whether an alert is associated with a galaxy. As we can see in the
sherlock features, SN and NT are NOT nearly as important as
we might have thought (in fact NT looks like it hinders a bit!).
This is likely a result of the fact that a lot of “extended” sources in the PS
catalogues are actually stars, and to be more complete with the SN tag
sherlock allows for a lot of contamination. For our model that means
that the SN category is not very informative, but using the separation
directly allows it to infer whether the source is likely to be a SN (they’re usually
offset, whereas stars and NT aren’t).
Finally note that z and photoz are now showing some importance,
as we expected.
day N features#
So what about the dayN models and the extra features we added?
The plots are big and bulky so I’m not adding them here, but you will be
able to find them in the paper or in the data release.
Here is the general gist.
For the real and galactic models the features that have the most impact are max_mag and max_mag_day.
For the real scorer DET_N_TOTAL (the total number of detections) so far
is also important. Everything else has little to no impact.
To be fair human eyeballers really rely on the forced photometry in this regime
to make decisions, so trying to tease out other features on the raw phot is
probably beating a dead horse. It was worth a go.